TL;DR:
- Enterprise cloud adoption is a strategic business transformation involving structured migration, governance, and operational practices to enhance scalability and efficiency. Successful adoption requires thorough dependency mapping, portfolio rationalization, choosing appropriate migration strategies, and establishing a Cloud Center of Excellence early to ensure security and cost control. Ongoing governance, cultural shifts, and continuous optimization are essential to sustain long-term enterprise success in the cloud.
Enterprise cloud adoption is defined as the structured process of migrating, transforming, and governing an organization’s IT infrastructure, applications, and data within cloud environments to achieve measurable gains in scalability, agility, and cost efficiency. This is not an IT project. It is a business transformation that reshapes how organizations build, operate, and compete. Frameworks like the AWS Cloud Adoption Framework (AWS CAF) and Microsoft’s Cloud Adoption Framework give CIOs and CTOs a repeatable structure for this shift, but the execution gap between planning and production remains wide. This guide covers the phases, risks, governance models, and operational realities that determine whether enterprise cloud adoption delivers on its promise or stalls in costly complexity.
What are the key phases of enterprise cloud adoption?
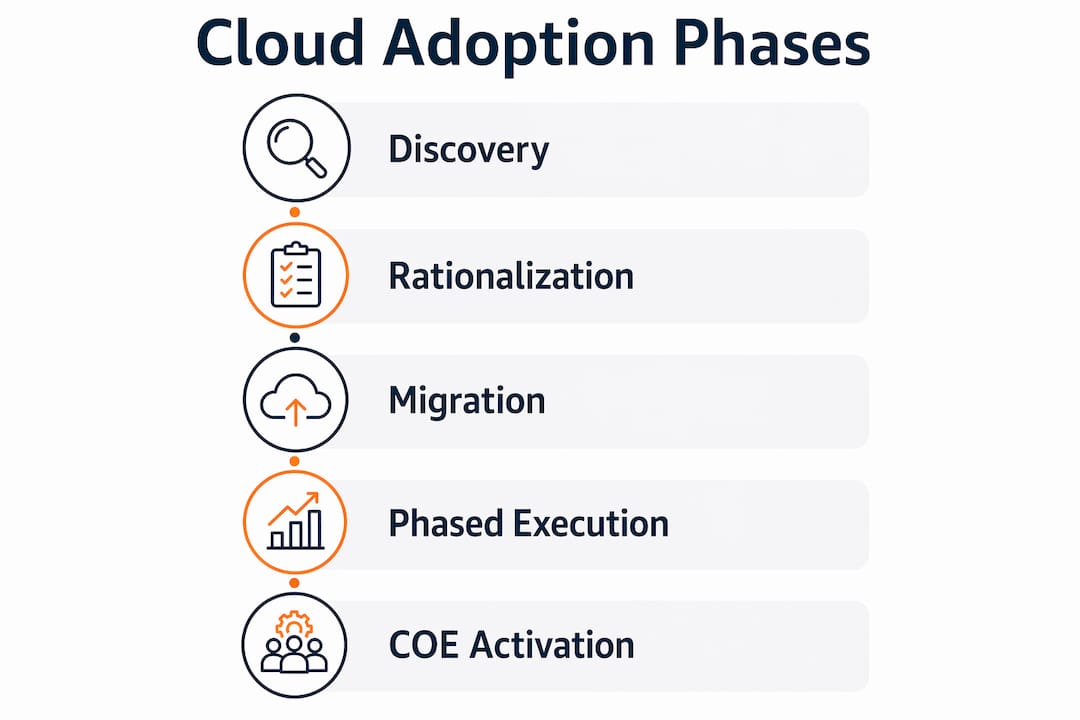
Enterprise cloud adoption follows a structured sequence. Skipping phases is the most common reason projects run over budget and over schedule.

Phase 1: Discovery and dependency mapping. Before any workload moves, you need a complete inventory of applications, infrastructure dependencies, data flows, and compliance requirements. Tools like AWS Application Discovery Service or ServiceNow Discovery automate much of this, but the output requires human validation. Incomplete dependency mapping is a direct cause of migration failures.
Phase 2: Portfolio rationalization. Not every application belongs in the cloud. Industry guidance recommends retiring 10 to 25 percent of the application portfolio before migration begins. Carrying legacy technical debt into a cloud environment does not eliminate it. It amplifies it, because migrating broken configurations results in higher operational costs and post-go-live instability.
Phase 3: Migration strategy selection. The three dominant approaches are rehosting (lift and shift), replatforming (lift and reshape), and refactoring (rebuild for cloud-native). Each carries a different cost, risk, and ROI profile. Lift-and-shift migrations without modernization yield approximately 40% lower ROI compared to cloud-native refactoring. That number should inform every migration strategy conversation you have with your architecture team.
Phase 4: Phased execution with go/no-go checkpoints. A phased migration approach limits failure impact by sequencing workloads from least complex to most critical, with rollback rehearsals built into each wave. Governance gates at each phase prevent a single failure from cascading across the portfolio.
Phase 5: Cloud Center of Excellence (COE) activation. A COE is a cross-functional team of architects, security engineers, finance analysts, and operations leads who own cloud standards across the enterprise. Early COE establishment prevents teams from recreating the same legacy bottlenecks in a new environment. Without it, you get shadow IT at cloud speed.
Pro Tip: Use the migration strategy selector to match each application to the right approach before committing to a migration wave. Applying one strategy across the entire portfolio is the fastest way to overspend.
How do enterprises manage cost, performance, and security during adoption?
Cost overruns and security gaps are the two failure modes that derail the most enterprise cloud programs. Both are preventable with the right architecture decisions made before migration begins.
Cost governance and FinOps
Cloud spending waste from idle and over-provisioned resources ranges from 25% to 35% without disciplined FinOps practices. FinOps, short for Financial Operations, is the practice of bringing financial accountability to cloud spending through shared ownership between engineering, finance, and product teams. The core disciplines include tagging policies, budget alerts, reserved instance planning, and right-sizing reviews on a monthly cadence.
- Set mandatory cost allocation tags before the first workload migrates. Retroactive tagging is expensive and rarely complete.
- Use a free cloud cost estimator during the planning phase to model spend across environments before committing to instance types.
- Establish a monthly FinOps review cycle with engineering leads and finance stakeholders from day one of production.
- Avoid over-provisioning at launch. Start with right-sized instances and scale up based on observed load, not projected maximums.
Pro Tip: Review the AWS cost optimization guide for specific tactics on reducing spend after go-live, including savings plans, spot instance strategies, and automated shutdown policies for non-production environments.
Security architecture before data moves
Security architecture design must precede data migration, not follow it. Retrofitting security controls after workloads are live is significantly more expensive and leaves exposure windows that auditors and attackers both find. The shared responsibility model defines what the cloud provider secures versus what the enterprise owns. AWS, Microsoft Azure, and Google Cloud all secure the physical infrastructure and hypervisor layer. The enterprise owns identity, access controls, network segmentation, data encryption, and application-level security.
Identity and access management (IAM) is the highest-priority control. Overly permissive IAM policies are the leading cause of cloud security incidents. Integrating enterprise identity controls using frameworks like Entra ID, SPIFFE, or Open Policy Agent (OPA) before migration establishes a zero-trust posture from the start.
| Security area | Common mistake | Correct approach |
|---|---|---|
| IAM | Broad admin roles assigned at account level | Least-privilege roles scoped to specific services |
| Network | Flat VPC with no segmentation | Subnet isolation with security groups per tier |
| Backup | Relying solely on cloud-native snapshots | Immutable external backup outside the provider ecosystem |
| Monitoring | Alerts configured post-launch | CloudTrail, GuardDuty, or equivalent active at migration start |
Cloud-native backup tools lack independent, immutable storage. Enterprises that rely exclusively on provider snapshots face total data loss risk in ransomware or accidental deletion scenarios. External backup solutions with write-once storage are non-negotiable for production workloads.
What lessons do enterprises learn from common cloud adoption mistakes?
The most instructive data point in enterprise cloud adoption is this: approximately 25% of organizations repatriate some workloads back on-premises after migration. Repatriation is expensive, disruptive, and almost always avoidable with better pre-migration analysis.
The root causes of repatriation and post-migration failure cluster around four patterns:
- Technical debt migration. Moving applications with known defects, outdated dependencies, or undocumented configurations into cloud environments does not fix those problems. It makes them harder to diagnose. Resolving critical technical debt before migration drastically improves stability and reduces operational costs after go-live.
- Resource sprawl. Without governance controls active from day one, teams spin up resources that never get decommissioned. Orphaned instances, unused storage volumes, and forgotten test environments accumulate silently and appear on the monthly bill.
- Delayed on-premises decommissioning. Many enterprises run parallel environments for months longer than planned because teams lack confidence in the new environment or because decommissioning criteria were never defined. This doubles infrastructure costs during the transition period.
- Missing success criteria. Governance models that include post-migration ownership and onboarding processes prevent new technical debt from accumulating. Measure success at 90, 180, and 365 days post-migration using defined metrics: cost per workload, incident frequency, deployment frequency, and mean time to recovery (MTTR).
The 90-day mark reveals whether the migration was executed correctly. The 180-day mark reveals whether the operating model is sustainable. The 365-day mark reveals whether the organization has genuinely transformed or simply moved the same problems to a different infrastructure layer.
Approximately 52% of cloud migration projects face cost overruns due to poor dependency mapping and lift-and-shift of legacy workloads. That majority outcome is not inevitable. It is the predictable result of treating migration as a technical task rather than a governed business program.
Which cloud adoption strategies sustain enterprise success long-term?
Getting workloads into the cloud is the beginning, not the end. The enterprises that extract lasting value from cloud adoption share a set of operational disciplines that most organizations underinvest in during the migration phase.
-
Operationalize the COE. The Cloud Center of Excellence should own cloud standards, review new architecture proposals, and run a monthly governance review. Without a standing COE, cloud decisions fragment across teams and the enterprise loses the economies of scale that justified the migration investment.
-
Build runbooks and knowledge transfer into the migration plan. Every migrated workload needs documented operational procedures: how to scale, how to recover, how to rotate credentials, and how to respond to alerts. Teams that skip this step create operational dependency on the individuals who executed the migration.
-
Adopt cloud-native services deliberately. AWS offers over 200 services. Azure and Google Cloud offer comparable breadth. The temptation to adopt services broadly creates complexity that outpaces the team’s ability to operate it. Prioritize services that directly address a documented business need: Amazon SageMaker for machine learning pipelines, Amazon Redshift for analytics, or AWS Lambda for event-driven workloads. Add services when the team has the skills to operate them, not because they are available.
-
Run continuous cost optimization reviews. Cloud cost optimization is not a one-time project. Right-sizing, reserved instance coverage, and savings plan utilization all drift over time as workloads change. A quarterly review cycle with engineering and finance prevents the 25 to 35 percent waste that accumulates without active management. The performance optimization guide covers specific techniques for maintaining efficiency as workloads scale.
-
Treat cloud adoption as a cultural shift. Cloud adoption requires a cultural and operational shift, not just technical migration. Engineering teams need to own cost outcomes, not just uptime. Product teams need to understand the cost implications of architectural decisions. Finance teams need real-time visibility into cloud spend. Leadership must model this accountability from the top.
Key takeaways
Successful enterprise cloud adoption requires governance, security architecture, and cultural accountability to be established before migration begins, not after.
| Point | Details |
|---|---|
| Retire before you migrate | Eliminate 10 to 25 percent of the application portfolio before migration to reduce complexity and cost. |
| Refactor beats rehosting | Lift-and-shift yields 40% lower ROI than cloud-native approaches; choose migration strategy by workload, not convenience. |
| FinOps from day one | Cloud spend waste reaches 25 to 35 percent without active FinOps practices; tag and budget before the first workload moves. |
| Security precedes migration | Design IAM, network segmentation, and immutable backup architecture before any data moves to the cloud. |
| Measure at 90, 180, 365 days | Define post-migration success criteria at three checkpoints to catch operational drift before it becomes technical debt. |
Why most cloud programs stall at the governance layer
After working through dozens of enterprise cloud programs, the pattern I see most often is not a technology failure. It is a governance failure that was predictable from the first planning meeting.
Organizations invest heavily in the migration itself, selecting the right tools, mapping dependencies, and running proof-of-concept workloads. Then they go live and immediately face a new problem: no one owns the cloud environment in the same way someone owned the data center. The COE was planned but never fully staffed. The FinOps process was documented but never enforced. The security architecture was designed but never validated against the actual production configuration.
The uncomfortable truth is that cloud adoption amplifies whatever organizational discipline already exists. If your change management process is weak on-premises, it will be weaker in the cloud because the speed of provisioning removes the natural friction that previously slowed bad decisions. If your security review process has gaps, those gaps become exploitable in minutes rather than months.
My recommendation to every CIO and CTO I work with is this: before you move a single production workload, spend 30 days getting your governance model right. Staff the COE. Define the tagging policy. Validate the IAM architecture. Write the runbooks for your first three workloads. That 30-day investment returns more value than any optimization you will do in the 12 months after go-live.
The enterprises that treat cloud adoption as a business transformation from the first conversation are the ones that hit their ROI targets. The ones that treat it as an infrastructure project are the ones repatriating workloads two years later.
— Oleksandr
Move to AWS with full execution ownership

IT-Magic has completed over 700 AWS migrations for enterprises in eCommerce and fintech, environments where downtime and security gaps translate directly into lost revenue. The approach covers the full lifecycle: infrastructure audit, migration strategy, hands-on implementation, and post-migration optimization. IT-Magic applies the right strategy for each workload, whether rehost, replatform, or refactor, always balancing speed, cost, and long-term maintainability. If your organization is planning a migration or has stalled mid-program, explore the AWS migration services that IT-Magic delivers, or review the migration best practices guide to benchmark your current approach against production-grade standards.
FAQ
What is enterprise cloud adoption?
Enterprise cloud adoption is the structured process of migrating and governing an organization’s IT infrastructure, applications, and data within cloud environments to improve scalability, agility, and cost efficiency. It encompasses assessment, migration execution, security architecture, and ongoing operational management.
What are the biggest risks in enterprise cloud migration?
The three highest-impact risks are cost overruns from poor dependency mapping, security gaps from incomplete IAM and network architecture, and post-migration technical debt from migrating broken configurations without remediation. Approximately 52% of migration projects face cost overruns due to these factors.
When does a hybrid cloud approach make sense?
A hybrid approach makes sense when specific workloads have latency requirements, regulatory constraints, or cost profiles that favor on-premises infrastructure. About 25% of organizations repatriate some workloads after migration, which indicates that a blanket cloud-first policy does not fit every enterprise portfolio.
How do you measure cloud adoption success?
Define measurable success criteria at 90, 180, and 365 days post-migration. Key metrics include cost per workload, incident frequency, deployment frequency, and mean time to recovery. Governance models that include post-migration ownership and onboarding processes prevent new technical debt from accumulating after go-live.
What is a Cloud Center of Excellence and why does it matter?
A Cloud Center of Excellence (COE) is a cross-functional team that owns cloud standards, architecture reviews, and governance across the enterprise. Early COE establishment prevents teams from recreating legacy bottlenecks in the cloud and supports repeatable delivery models that scale as adoption expands.