TL;DR:
- Most IT teams underestimate the complexity of end-to-end migration, which involves multiple structured stages beyond simple data transfer. Recognizing it as a comprehensive lifecycle—including discovery, planning, pilot testing, execution, validation, and cleanup—ensures smooth cloud transitions and minimizes post-migration issues. Following best practices like thorough discovery, pilot validation, and staged cutovers reduces downtime, enhances data security, and improves long-term scalability for organizations.
Most IT teams underestimate what end-to-end migration actually involves. They picture it as moving data from point A to point B, maybe with a weekend maintenance window and a Monday morning rollout. The reality is considerably more involved. Understanding end-to-end migration means recognizing it as a structured, multi-stage process that spans infrastructure audits, parallel operations, phased cutovers, and post-migration cleanup. For IT professionals and business leaders navigating cloud transitions, grasping the full scope of this process is what separates projects that go smoothly from ones that generate incident reports for months afterward.
Table of Contents
- Key takeaways
- What end-to-end migration actually involves
- Frameworks and best practices for managing migration projects
- Big bang vs. phased migration: choosing the right approach
- Technical and operational considerations for migration success
- End-to-end migration benefits for businesses and IT teams
- My take on what most migration guides get wrong
- How Awsmigrationservices handles end-to-end AWS migrations
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Migration is a lifecycle, not an event | End-to-end migration covers discovery, design, pilot, execution, and validation as connected stages. |
| Pilot migrations are non-negotiable | Skipping the pilot phase is one of the most common causes of costly mid-migration rework. |
| Discovery quality determines outcome | Finding data quality issues early costs far less than discovering them during full-scale execution. |
| Rollback plans require rehearsal | A well-rehearsed rollback process can reverse a failed cutover in under ten minutes. |
| Post-migration cleanup matters as much as the move | Failing to decommission legacy components properly causes performance issues and security gaps after cutover. |
What end-to-end migration actually involves
The phrase “end-to-end migration” describes the complete lifecycle of moving workloads, systems, or data from one environment to another, covering every phase from initial assessment through final decommissioning. It is not limited to data transfer. It includes the decisions made before a single byte moves and the cleanup work done after the last server goes dark.
A well-structured end-to-end migration process typically moves through five core stages:
- Discovery and assessment: Auditing the existing environment, profiling data sources, mapping dependencies, and identifying compliance or security constraints
- Planning and architecture design: Defining the target architecture, selecting migration strategies (rehost, replatform, or refactor), and setting validation criteria
- Pilot migration: Moving a representative subset of workloads to test the process, catch data quality issues, and validate tooling before full-scale execution
- Full-scale execution: Migrating the remaining workloads in planned waves, with parallel systems running and data synchronization active
- Post-migration validation and optimization: Confirming data integrity, tuning performance, decommissioning legacy infrastructure, and closing out documentation
One important distinction: data migration, application migration, and full system migrations are related but not interchangeable. Data migration moves information between storage systems. Application migration moves software and its dependencies. Full system migration does both simultaneously, often across different infrastructure paradigms. Enterprise cloud transitions usually involve all three, which is precisely why the end-to-end framing matters.
Pro Tip: Parallel operations, where old and new systems run simultaneously with synchronized writes, are the difference between a reversible migration and one that forces you to choose between a bad outcome and a worse one. Build dual-write capability into your architecture before the first wave of traffic shifts.
Enterprise-level migrations for large organizations typically require four to eight weeks of structured, phased work to achieve zero downtime. That timeline is not padded. It reflects the actual cost of doing discovery, running a pilot, executing in waves, and validating thoroughly.

Frameworks and best practices for managing migration projects
The industry has converged on a five to seven stage framework for enterprise migrations. The exact number of stages varies by organization, but the phases that cannot be skipped are consistent: discovery, design, pilot, execution, and validation. Teams that try to collapse those phases into fewer steps usually encounter the problems the phases were designed to prevent.
Here is how a best-practice framework sequences these activities:
- Inventory and discovery: Document every data source, application dependency, API integration, and compliance requirement. This phase defines the scope of everything that follows.
- Data profiling and quality assessment: Identify structural inconsistencies, duplicates, and missing values before designing transformation rules. Finding data quality issues at this stage costs ten times less than fixing them mid-migration.
- Architecture and strategy design: Select migration patterns, define transformation logic, and establish validation criteria and acceptance tests.
- Pilot migration: Move a small, representative cohort of workloads. Validate the process against pre-defined criteria. Do not proceed to full-scale execution until pilot results meet those criteria.
- Full-scale execution in waves: Migrate workloads incrementally, with rollback capability active at each wave.
- Validation and reconciliation: Confirm data integrity end-to-end. Run parallel systems long enough to catch timing-related anomalies.
- Decommissioning and closeout: Retire legacy infrastructure in proper sequence, close documentation, and transfer operational ownership.
“Skipping the pilot phase is a non-negotiable risk leading to costly rework.” This observation from enterprise data migration practice holds true regardless of the technology stack involved.
Migration engineering has also evolved toward a contract-based model that codifies validation rules, transformation logic, and rollback triggers as formal specifications. This removes ambiguity about what constitutes a successful migration and makes automated verification possible at each stage checkpoint.
Pro Tip: Treat your migration plan as a contract, not a roadmap. A roadmap tells you where you are going. A contract specifies the exact conditions under which you move from one phase to the next, and what happens if those conditions are not met.
Mid-sized organization migration timelines vary significantly. Standard projects can complete in 20 to 28 business days while complex enterprise environments may require additional weeks of reconciliation time. Build that variability into stakeholder expectations from the start.
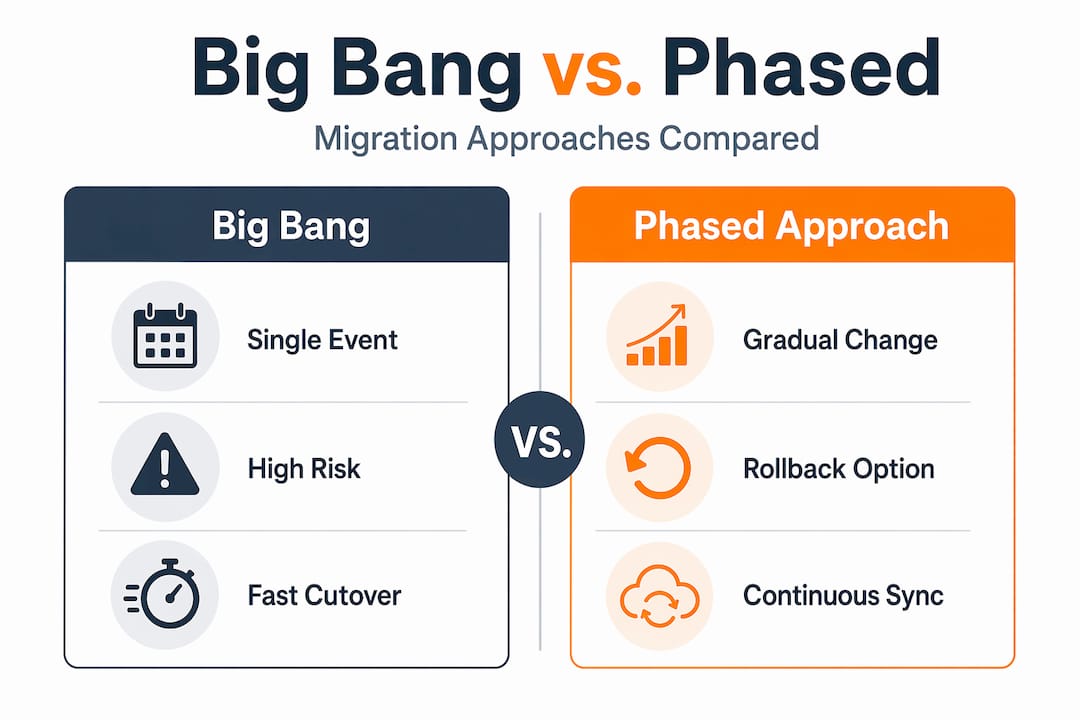
Big bang vs. phased migration: choosing the right approach
Every migration team faces a fundamental choice between two execution models. That choice has real consequences for downtime, cost, and risk exposure.
Big bang and phased migrations represent opposite ends of the risk-speed spectrum. Big bang moves everything at once during a defined maintenance window. Phased migration moves workloads incrementally over weeks or months, with both environments running in parallel for part of that period.
| Dimension | Big bang migration | Phased migration |
|---|---|---|
| Execution speed | Fast, single cutover event | Slow, incremental over weeks |
| Downtime risk | High, extended window required | Low, parallel systems minimize exposure |
| Cost complexity | Lower initial cost | Higher, due to dual infrastructure costs |
| Error detection | Late, post-cutover | Early, incremental validation possible |
| Rollback difficulty | Very difficult once committed | Easier, reversible at each wave |
| Best suited for | Small systems, low transaction volume | Enterprise environments, high-load systems |
Phased migration is the preferred approach for enterprise environments precisely because it preserves rollback flexibility at each increment. The cost of running parallel systems is real, but it is almost always lower than the revenue impact of extended downtime on a production system.
Big bang migrations make sense in specific contexts: systems with low transaction volumes, clean data with few dependencies, or situations where the legacy environment cannot support long-running parallel operations. For eCommerce platforms or fintech systems processing real-time transactions, big bang is rarely the right choice.
Phased cutover ramps traffic gradually from 1% to 100% over weeks, with rollback capability and continuous synchronization of dual writes to avoid data loss. That gradual ramp is not caution for its own sake. It is an engineering mechanism for catching problems at a scale where they are still fixable.
Technical and operational considerations for migration success
Knowing the framework is necessary but not sufficient. The difference between a migration that goes well and one that generates a post-mortem is usually found in the execution details.
The pilot-then-scale approach is the single most effective risk mitigation technique available. Pilot migration validates the entire process against real data and real system behavior before you commit to full-scale execution. Teams that skip the pilot because they feel confident in their tooling tend to discover their confidence was misplaced at the worst possible moment.
Key technical considerations that require explicit planning include:
- Feature flags for cutover control: Traffic routing decisions should be runtime-mutable, not hardcoded. Rollback plans should allow instant traffic flipback, and a well-rehearsed rollback can occur in under ten minutes when those flags are in place.
- Cohort-based cutover patterns: Moving traffic per-tenant or per-user cohort rather than all at once limits blast radius if something goes wrong. An AWS migration checklist should include explicit cutover segmentation criteria.
- Monitoring and validation during execution: Alerting thresholds and reconciliation checks should be active throughout the migration, not just at the end. Real-time discrepancy detection prevents small issues from compounding.
- Post-migration cleanup sequencing: Retiring webhooks, APIs, and legacy servers requires a specific order. Proper decommissioning sequence only happens after full migration validation. Teams that rush decommissioning to reduce costs often reintroduce the performance and security issues they migrated to escape.
Pro Tip: Schedule a dedicated decommissioning sprint after migration validation is complete. Treating cleanup as an afterthought is how you end up with a new cloud environment that still depends on legacy systems nobody officially manages anymore.
Post-migration performance optimization is also a distinct phase, not just a checkbox. Right-sizing compute resources, tuning database configurations, and reviewing network topology in the new environment often yield cost and performance improvements that the migration itself made possible but did not automatically deliver.
End-to-end migration benefits for businesses and IT teams
Organizations that execute end-to-end migration with full lifecycle discipline realize measurable improvements that partial or rushed migrations typically do not achieve. Understanding the end-to-end migration benefits helps business leaders make the case for investing in the process correctly.
The advantages fall into four categories:
- Reduced downtime and customer impact: Phased execution and rollback capability mean that problems during migration affect a fraction of users rather than everyone. Zero-downtime migrations are achievable for complex systems when the process is followed correctly.
- Improved data integrity and security: Systematic validation at each phase catches corruption and consistency issues before they propagate. Security controls configured in the discovery phase carry through the entire migration rather than being retrofitted at the end.
- Greater agility and scalability post-migration: Cloud environments designed as part of a structured migration process are architected for scale from the start. Organizations can unlock cloud scalability in ways that lift-and-shift migrations without full lifecycle planning rarely deliver.
- Cost efficiency and technology alignment: Infrastructure right-sized during migration costs less to operate. Technical debt addressed during the refactor phase reduces the ongoing cost of maintaining legacy code in a modern environment.
My take on what most migration guides get wrong
I have worked through enough migration projects to have strong opinions about where things go sideways, and the pattern is consistent. The failures rarely happen during execution. They happen in the weeks before it, when discovery gets compressed because stakeholders want to see progress.
Rushing discovery is the most expensive mistake in migration. Teams that spend two weeks on discovery when four are needed will spend that time again, plus more, fixing data quality problems that a proper audit would have caught. The math is straightforward, but the organizational pressure to move faster is real and persistent.
The second thing most guides miss is that rollback rehearsals need to be treated like fire drills, not theoretical options. I have seen teams confident in their rollback plan until they needed to use it and discovered that the plan had never been tested against actual production traffic volumes. A rollback you have never practiced is a plan, not a capability.
Post-migration cleanup also gets systematically underestimated. Legacy systems left running “just in case” become permanent fixtures that nobody owns, generating costs and security exposure for years. The end of a migration project should include a hard decommission deadline with accountability attached to it.
What I find genuinely effective is treating the pilot migration as a full dress rehearsal, not a quick test. Run the pilot against representative data volumes, execute the rollback procedures even if everything went fine, and use the results to update your execution runbook before scaling up. That practice alone separates migrations that go according to plan from ones that require improvisation under pressure.
— Oleksandr
How Awsmigrationservices handles end-to-end AWS migrations

Awsmigrationservices was built specifically for the complexity that makes organizations hesitate before committing to cloud migration. As an AWS Advanced Tier Partner with 700+ completed projects, Awsmigrationservices takes full ownership of every phase: infrastructure audit, architecture design, pilot execution, full-scale migration, and post-migration optimization. You do not get a plan and a handoff. You get a team accountable for outcomes.
The approach is structured around the same lifecycle described in this article, applied to high-load environments in eCommerce and fintech where downtime translates directly into revenue loss. Whether the right strategy is rehost, replatform, or refactor, Awsmigrationservices selects and executes based on your specific environment and risk profile.
If you are ready to move to AWS without the incident reports, explore what end-to-end AWS migration looks like when execution is handled by specialists who have done it 700 times before. You can also review AWS migration best practices to see how structured methodology translates into predictable results.
FAQ
What is end-to-end migration?
End-to-end migration is the complete process of moving workloads, applications, or data from one environment to another, spanning discovery, planning, pilot testing, full-scale execution, and post-migration validation. It covers every phase from the initial audit through final decommissioning of legacy systems.
How long does an end-to-end migration take?
Timelines vary by complexity. Enterprise migrations typically take four to eight weeks, while standard mid-sized projects can complete in 20 to 28 business days. Complex environments with legacy dependencies may require additional reconciliation time.
What does end-to-end migration involve at each stage?
It involves discovery and assessment, architecture design, pilot migration, full-scale execution in waves, validation and reconciliation, and structured decommissioning of the legacy environment. Each stage has defined entry and exit criteria.
What is the difference between big bang and phased migration?
Big bang migration moves everything in a single cutover event, which is fast but risks extended downtime. Phased migration moves workloads incrementally over weeks with parallel systems running, enabling early error detection and easier rollback.
Why is the pilot phase so critical in end-to-end migration?
The pilot phase validates the entire migration process against real data before full-scale execution begins. Skipping it is one of the most reliable ways to create expensive rework, because errors that appear in pilot are far cheaper to fix than errors discovered after a full production cutover.